Scratchpad Memory Management Unit
A data cache alternative for hard real-time systems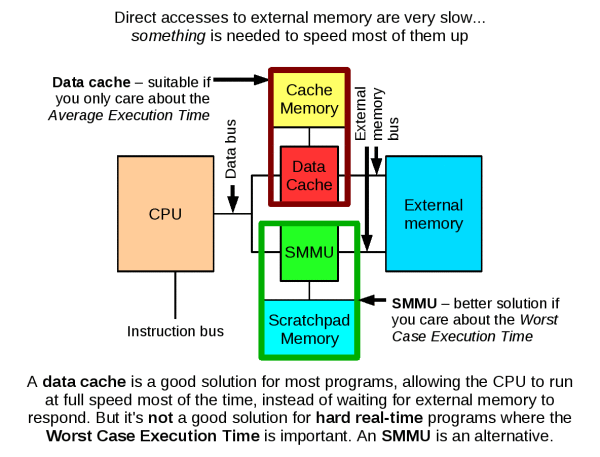
The scratchpad memory management unit (SMMU) is a hardware device that makes it easier to use a scratchpad RAM (SPM) from a conventional C program.
SPM can be used to speed up programs and reduce the energy they consume, both of which are important in mobile devices such as the Nintendo DS. However, the purpose of the SMMU is time predictability, a second advantage of SPM. In a hard real-time system, it is important to know the upper bound on the execution time of a program, and that means knowing the upper bound on the execution of each instruction in the program, at least in some sense. This is not always easy! Load and store instructions, which access the computer's memory, are particularly problematic especially if a cache is used, because the memory access times (latencies) depend on the contents of the cache, and the contents of the cache depend on earlier references to memory (the "reference string").
With the SMMU, the programmer or compiler can declare which data objects should be stored in SPM, guaranteeing low-latency accesses to those objects. This eliminates dependence on the reference string. It is similar to the well-known processes of locking objects into cache, or copying objects into SPM, but the SMMU eliminates the following important concerns:
- Objects may conflict in cache, making it impossible
to lock all of them simultaneously.
(A cache assigns objects to lines based on some of the address bits. An N-way set-associative cache can only lock N objects simultaneously, because object N+1 could conflict with any of the others. Additionally, the mapping makes poor use of cache space unless all objects exactly fill their assigned "way".)
- When objects are copied into SPM, their addresses change.
This can change the behaviour of a program unless all pointers
to the objects are updated, otherwise a pointer may reference
a stale copy of the object.
(Identifying all those pointers is not easy. It is a form of pointer aliasing problem: not possible for programs in general.)
The benefit: dynamic data structures can be used within time-predictable software. The SMMU enables the use of object-oriented programming techniques in hard real-time code, along with advanced algorithms that are not suitable for conventional SPM and cache analysis techniques.
Address Transparency
The SMMU implements address transparency. An object can be relocated to SPM without changing its logical address, the address used by the program. Relocation does not invalidate any pointers and causes no issues related to pointer aliasing.
This feature is provided by the SMMU's remapping table. It takes addresses generated by the CPU, and compares them to the addresses of the objects currently loaded into SPM. If there is a match, the access is redirected to the SPM. The program notices no difference (except that the access is very fast). Otherwise, the access goes on to external memory.
This makes it easy to store heap data (e.g. dynamic data structures) within SPM while retaining fully time-predictable memory accesses. The programmer or compiler need only state which objects should be in SPM. Objects may be moved between SPM and external memory at any time. There is no need to update any pointers to reflect such a transition.
Efficient use of SPM space
The remapping process can place objects at arbitrary SPM addresses. This means that SPM space can be used very efficiently. Objects do not need to take up an entire cache way: potentially, all of the SPM space can be used.
Time-predictability
Any "load" or "store" instruction has single-cycle latency if the object being accessed is in SPM. A local data flow analysis reveals if the "load"/"store" uses a pointer that is guaranteed to be in SPM: given this information, worst case execution time (WCET) analysis can determine an estimate for the maximum execution time of the program (provided that the program is otherwise suitable for WCET analysis).
In SMMU terminology, we say that an object in SPM is "OPEN". Programs OPEN the objects that are likely to be accessed repeatedly. This terminology has been chosen because of the similarity to opening a file on disk, e.g. with "fopen". If the file will be accessed repeatedly, a well-behaved program will typically keep it open, rather than repeatedly running the sequence fopen/update/fclose. This is because fopen and fclose incur a time overhead, which becomes very significant if the operations are used repeatedly. So, smart programmers keep files open whenever possible.
Similarly, programs should keep data on-chip whenever possible, to avoid the overhead of transferring it to and from external memory. A cache handles this job implicitly: easy to use, but not time-predictable. An SMMU places the task of OPENing and CLOSEing objects in the hands of the programmer or compiler: more difficult to use, but time-predictable.
Hardware and Software Downloads
SMMU hardware designs are available under the GNU Lesser General Public License version 2.1.
The first release of the hardware and software was in April 2009.
The current version, released March 2010, is 1.03: smmu_kit_1.03.tar.bz2. This includes support for read-only objects. As with many aspects of the SMMU's design, the devil is in the details, and read-only object support proved to be quite tricky to implement correctly. A big issue with SMMU design is dealing with OPEN objects that overlap in memory, and this becomes even more difficult when some of the objects may be read-only. Writes to objects OPENed as "read-only" may occur in correct programs due to pointer aliasing, so it was very important to handle this situation.
The downloadable software and hardware should be enough to incorporate the SMMU into your own hardware designs and experiments. Hardware experiments will be particularly easy if you have access to the Xilinx EDK tools, since you will be able to use the SMMU with the Microblaze CPU and other Xilinx components. The designs have been tested with tool versions 10.1 (SP3) and 11.3.
Publications
To date, there are four SMMU publications other than this web page.
- The SMMU technical report is the
earliest.
This describes the implementation of the SMMU (version 1.00) for Microblaze in detail. Notable points are (1) how the interface to Microblaze actually works, and (2) how overlapping objects are handled.
- "Implementing Time-predictable Load and Store Operations"
(PDF link) was presented at EMSOFT 2009.
It deals primarily with evaluation of the SMMU for Microblaze, based on the "jpeg-6b" case study. The paper was well received at the conference with plenty of questions and subsequent discussion (see Criticism, below).
- "Studying the
Applicability of the Scratchpad Memory Management Unit"
(PDF link) was presented at RTAS 2010.
This paper uses an allocation algorithm to examine the effect of adding OPEN and CLOSE operations to various benchmark programs. It's entirely based on simulation, but we know how OPEN and CLOSE will work if implemented "for real" because of the earlier work. For this paper, there is a software package containing the code that produced the results. The results show that the SMMU is useful on real code, but not in all cases, because certain access patterns exhibit poor locality, and others have good locality but require transformation before OPEN and CLOSE can be used effectively.
- "Investigating
average versus worst-case timing behaviour of
data caches and data scratchpads"
(PDF link) was presented at ECRTS 2010.
This paper compares the SMMU+scratchpad to a data cache using a variety of loop kernels captured from benchmark programs. It proposes and evaluates solutions to the issues raised in the RTAS 2010 paper, and finds that the SMMU and cache actually have very similar performance on average. However, the SMMU+scratchpda combination is much more predictable and has excellent worst-case performance as well. A software package containing the experiment code and raw data is now available.
Criticisms of the SMMU
There are three major technical criticisms.
- One is that the comparator
network used by the SMMU effectively lowers the clock frequency of
the host CPU, as it is connected to the ALU output in a RISC design
(e.g. Microblaze). This is true, and as published data
shows, the clock frequency is reduced further as the comparator
network size is increased. We are considering several options to reduce
this effect. However, we find that fairly high clock frequencies can
still be achieved on FPGA without taking steps such as manual
placement and routing.
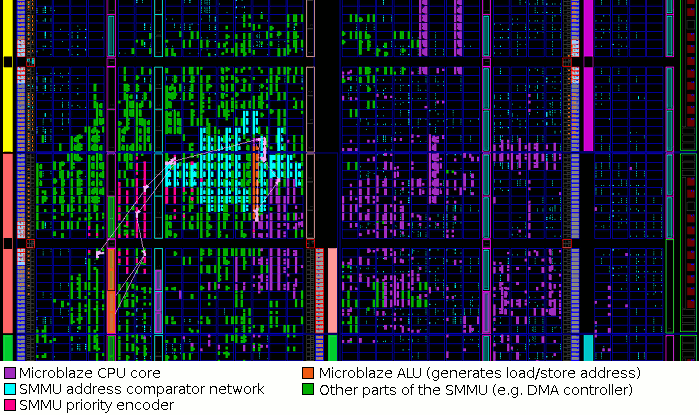
For example, the above image shows the FPGA floor plan of the SMMU combined with Microblaze. Here, the system clock frequency is 100MHz, and the three most critical paths are shown. Notice that the Microblaze ALU is surrounded by the SMMU's comparator table in order to minimise the critical path delay: this arrangement was discovered entirely automatically by the Xilinx tools. This Virtex-5 FPGA has speed grade "-1" (the slowest possible), and yet the SMMU and Microblaze can operate at nearly 110MHz. (This system is included in smmu_kit_1.03.tar.bz2.) Much higher frequencies would be possible with manual placement in an ASIC design process. - Secondly, the compiler (or worse, the programmer)
will be forced to add instructions to OPEN and CLOSE things, and this
will include selecting a place within SPM for each object.
For every OPEN, the compiler will need to be aware of what else
could be OPEN at that point, in order to be sure which SPM areas
are occupied. Although this doesn't require knowledge of the logical
addresses of the other objects, it does limit the structure of the
program:
- Recursion is difficult to handle. If a procedure uses OPEN and then calls itself, the second call to OPEN must use a different address in SPM. This is difficult to arrange: how is the new address obtained?
- The SPM could contain areas of free space that are unusable because of fragmentation. This will be a particular issue if a procedure uses OPEN and may be called from more than one context: the different contexts may have different OPEN objects.
- Similarly, if OPEN is placed on one control flow path leading to a basic block X, but not on another, then the state of the SPM at X is uncertain. (This is easily avoided by the use of scoping rules to restrict the placement of OPEN and CLOSE.)
- Finally, it is argued that the SMMU provides no advantage over WCET
analysis for caches, because the WCET tool still needs to be aware of
what data is on-chip at each point in the program. This is not true.
The problem is greatly simplified.
The contents of a cache are dependent on the reference string generated by the code, i.e. addresses passed to "load" and "store", as well as the path through the code. The cache analysis is forced to use an abstraction to handle this, with a resulting loss of precision (but not safety). However, the contents of SPM using the SMMU are dependent only on the path through the code, and then only on the OPEN and CLOSE operations that have been reached. The reference string is irrelevant along with all other instructions. Therefore, no abstraction is required to represent the SPM state, and the analysis problem is a simple matter of using the control-flow graph (CFG) to determine whether every path from a "load" or "store" (1) leads to an OPEN using the same pointer, and (2) is uninterrupted by a CLOSE operation matching that OPEN. This is a vast simplification of a very difficult problem, and one that does not require whole-program pointer analysis.
Roadmap
Research is ongoing. In future I will be focusing on integration of SPM/SMMU control into a compiler, most likely based on the LLVM technology. This will enable further research into the applicability and costs/benefits of the technology.
But I also want to encourage other people to think about using scratchpads for real-time and embedded systems, with and without the SMMU, and I welcome feedback, suggestions and criticisms. I'm also providing the source code and hardware designs and you are welcome to make use of this for your own work.