Submission: Explicit Reservation of Cache Memory in a Predictable, Preemptive Multitasking Real-time System
Friday, 6 July 2012
Last Friday I submitted a paper to the ACM journal "Transactions in Embedded Computing Systems" (TECS). The paper began as a simple extension of a paper presented at the RTAS 2012 conference, revised and improved for the journal. But in the two months that I was working on it (May-June) it evolved into much more.
The weaknesses of the original paper were (1) an imprecise schedulability analysis, which was safe but inaccurate, (2) an over-reliance on simulation for experiments, and (3) a very high degree of complexity caused by simultaneously introducing new hardware, a new task execution model, and a new form of memory management - all in one paper!
It turns out to be a bad idea to try to pack so much into a single paper, even a journal paper, because you cannot deal with any one of the topics in an acceptable level of detail. Worse still, the details of your results will be obfuscated: it will not be clear where each improvement is coming from. For instance, does the improvement come from the benefits of the multitasking scratchpad reuse scheme (MSRS), or does it come from some other benefit of scratchpad memory (SPM)?
I tried to deal with all three weaknesses in the new version of the paper.
I was assisted with the first by Rob Davis, who helped me revise the equations in the original RTAS submission, and is a co-author on the version sent to ACM TECS. Rob Davis provided an entirely new exact schedulability test for this version of the paper, which goes alongside the (less accurate) sufficient test that we used in the recent RTSS submission. The sufficient test turns out to get results that are very close to the exact test, but there is still a small degree of pessimism.
To reduce the reliance on simulation, I implemented a simplified version of the hardware required by the original paper on FPGA. Part of the work had already been done for the RTSS submission; in principle I only needed to add support for a data SPM. After about a month of work, this was implemented as the Carousel component, supporting Save, Restore, Load and Writeback operations.
But the third issue, namely the density of the paper, turned out to be the real problem. The work needed to be closely focused on the properties of MSRS. I needed to isolate these from the benefits of using SPM - but without completely undermining SPM.
This turned out to be more difficult than expected. The relevant benefit of SPM is that it allows the program to load an arbitrary amount of code and data in a single pipelined burst transfer (a very effective use of the memory bus). If this is used, then SPM is typically better than cache, because cache accesses occur when implicitly required, and not normally ahead of time (even prefetching does not normally fetch entire functions and entire data structures ahead of time).
However, if this benefit is not used -- if the SPM is filled one cache block at a time, with no pipelining -- then the overhead of initiating the SPM operations means the execution time of each task is greater than cache. SPM is worse than cache. This undermines the benefits of MSRS. The whole solution looks bad because the SPM is not being used effectively.
So, I could not properly isolate the benefits of SPM and the benefits of MSRS. The two were entwined together.
I decided upon a small change of direction. Over the last few years, Neil Audsley and myself have been thinking about hybrid cache and SPM architectures. Our original idea was that these might be useful for real-time systems that also needed to run non-real time tasks. However, there is another application.
I realised that something very like MSRS could be applied to a cache architecture. The cache would work as a cache for the purposes of running tasks, but it would be treated as an SPM for the purposes of switching between them.
It doesn't make sense to call this MSRS, so instead I called it Explicit Reservation of Cache Memory. But it works just like MSRS. When the RTOS starts a new task t, it saves the state of n cache blocks for that task. This is the cache budget fort, which is only permitted to use thesen cache blocks. When the task finishes, the previous state of the blocks is restored. The cache is dynamically partitioned.
Because the save and restore operations take time, there is acache related preemption delay (CRPD). But this is potentially smaller than the CRPD observed if multiple tasks just share the same cache, and evict blocks used by each other. The main reason why it is smaller is that the restore operation works like a SPM load. It is pipelined. Rather than allown cache misses to occur at some unknown future time, the RTOS carries out the required cache fill operations in one go. This is much faster.
For example, on my FPGA platform, a cache miss takes 27 clock cycles. A single cache fill (n =1) also requires 27 clock cycles. But two cache fills, pipelined, require only 38 clock cycles as opposed to 56. Three require 49 as opposed to 81.
By writing the paper about explicit reservation ofcache, as opposed to SPM, I was able to focus on the specific benefit of reducing CRPD costs. The paper compares the situation where all tasks share a cache with the situation where each task has an explicitly-reserved area of cache.
Here are some results from the paper -
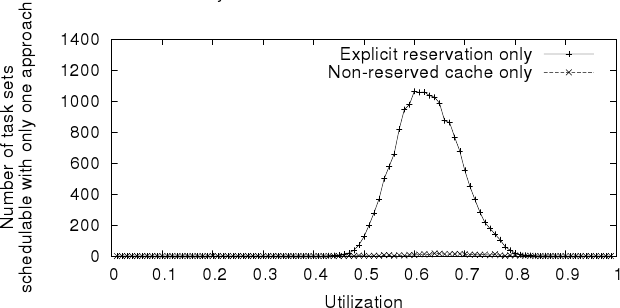
This is a test of task sets of size 40. For each task set utilisation 0.01 to 0.99, a program generated 10000 task sets. I then tested whether each task set would be schedulable or not, based on (1) the CRPD analysis from Altmeyer, Davis and Maiza, which assumes the caches are shared between all task, and (2) explicit reservation.
Most task sets are schedulable with both approaches or neither approach. This graph plots the number of task sets that were schedulable with only one. As you can see around utilisation 0.6 and 0.7, a small number are schedulable only with the shared cache, but a much greater number are schedulable only with explicit reservation. That's because the CRPD has been greatly reduced. For some task sets, the extra overhead of explicit reservation is still too much, and a plain cache is better. But those cases are a minority. (They become less frequent if we have more tasks, and more frequent with fewer tasks... the paper deals with that topic in more detail.)
It's a good result which confirms earlier work and shows that it applies more widely. The benefits of explicit reservation are not limited to SPM, they also apply to cache. I am also pleased because I think that this result has allowed me to present the approach in a much simpler form, in which it is clear where the benefit is coming from.