More fun with floating-point numbers
Saturday, 18 April 2015
Last week's post on compiler optimisations and floating-point numbers got some interesting feedback, including various suggestions for hardware/software workarounds, and also some horror stories, which you may find here.
The spot-the-difference puzzle was admittedly rather difficult. Here's an easier one:

That difference is the result of a 64-bit specific memory corruption bug, caused by misuse of "sizeof". Left hand side is correct (x86). Right hand side shows the bug (AMD64). The fix is here. Quake 2 managed to render a single frame before crashing spectacularly, and I was pleased to find that the effect that had caused the crash is actually visible in the transparent texture on the right-hand side of the frame.
There is one correction to last week's post. It is possible to put the x87 FPU into 32-bit or 64-bit mode by setting two bits in a control register. The default is 80-bit mode (on Linux at least) but a process can change this. The setting applies to the whole process, including library functions, and this can be another source of bugs. I understand that the GCC options -mpc32 and -mpc64 will set these modes during startup. Here is some suggested reading on the subject of floating-point issues for C/C++ programmers, showing (amongst other things) that it's really not just a Linux thing or an x86 thing.
Anyway, I continued to work on my Quake 2 benchmark/test project, and made something of a breakthrough with a change that made the AMD64 and ARM results almost entirely match the x86 results. The change resolved another floating point "bug", again activated by optimisations, but this time only affecting the AMD64 and ARM builds.
Quake 2 uses the "sin" and "cos" functions in various places, e.g. the AngleVectors function. In the standard math.h header, "sin" and "cos" operate on the 64-bit "double" type, but Quake 2 calls them with 32-bit "float" types, so GCC implicitly converts floats to doubles in unoptimised mode.
In optimised mode (-O2), GCC tries to be smarter. It substitutes "sin" and "cos" with equivalents that operate directly on the 32-bit "float" types: "sinf" and "cosf". This change in the internal precision of the "sin" and "cos" operations causes small differences in the result: "sin" uses doubles internally, and "sinf" uses floats. So, the compiler's choice of "sinf" instead of "sin" is another example of a compiler optimisation that can affect the result of a program.
But this time, the problem does not show up on x86 at all! It was only seen on AMD64 and ARM. Why was x86 immune?
The reason turned out to be that "sinf" and "sin" are equivalent on x86 if a "float" is passed in, because both of them operate at the same precision internally. They both use the x87 instruction "fsin" which always has the same precision (80 bits, I assume). Consequently "sinf(x)" actually is the same as "(float) sin ((double) x)". But only on x86!
The solution to this bug was to either (1) replace "sin" with "sinf" everywhere, doing the same for other floating-point library functions, or (2) use a different math library, or (3) prevent GCC using the optimisation. I opted for the third approach, disabling the optimisation with "-fno-builtin". This is somewhat inefficient, as there are unnecessary type conversions and the function itself is over-precise, but it allows me to use x86 as a reference. platform.
That change, coupled with several other bug fixes, means I can run the Q2DQ2 demo from beginning to end (about 17000 frames, rendered at exactly 25fps), and then use the CRC32 of every frame for comparison between different builds. The results are almost consistent across all platforms:
- x86, built with -O0 (reference)
- x86, built with -O2 (output is exactly the same as x86 -O0)
- ARM, built with -O0 (output is exactly the same as x86 -O0)
- ARM, built with -O2 (7 of 17000 frames don't match x86 -O0)
- AMD64, built with -O0 (output is exactly the same as x86 -O0)
- AMD64, built with -O2 (2 of 17000 frames don't match x86 -O0)
It seems there are still at least two bugs, one ARM specific, and another appearing for both AMD64 and ARM. A little more debugging is required.
So far, the strangest bug I found is an issue that may never have been found before. It's in at least one Quake 2 source port (yquake2), it is found in both the OpenGL and software 3D renderer, and it is subtle. It concerns animated, transparent textures, like the one shown here:
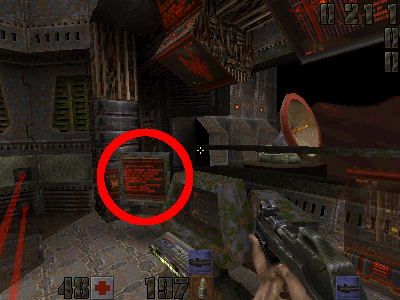
This transparent computer screen is an animated texture, but you might never have noticed it animating, even if you have played this Quake 2 level many times. The animation remains stuck on a single frame.
The thing is, the frame number that it remains stuck on depends on the sorting order of entities in the level, because it's taken from the final entity that was processed. In turn, that sorting order depends on the locations of those entities in memory, i.e. where the heap allocator put them! I found that the animation is stuck on frame 1 on x86, and frame 4 on ARM, just because the entities were put in different places in memory, and the final entity on the list was different. The frame number should be taken from the level itself, rather than any entities within it, because that's how all other animated textures work. But transparent textures are special. Unlike other textures, they're processed after the list of entities has been used, and walking through that entity list clobbers the frame number. I noticed the bug because the behaviour was visibly different on the two platforms, which showed up in my CRC32 check. Here is my fix.