Why is this taking so long? - the poor man's profiler and flame graphs
Saturday, 21 March 2015
Have you heard of the "poor man's profiler"?
A "sampling profiler" interrupts a program at regular intervals, taking a sample of the state of each thread. Often, a program must be executed by the profiler in order to do this, but that is not absolutely necessary. Sometimes it can be awkward to restart a long-running program. In these cases you can use a debugger as an alternative to a "real" profiling tool. The results are not usually very accurate, but they can still be useful.
The method is as follows: attach to the tool's process using a debugger such as gdb, print out a stack trace, and then detach. Repeat this process using a script to drive gdb.
This takes a snapshot of what the program is doing at that particular instant. Here is an example of a stack trace:
Thread 1 (process 10045):
#0 0x0000000000424ec5 in R_DrawColumn () at r_draw.c:157
#1 0x0000000000427b4d in R_RenderSegLoop () at r_segs.c:287
#2 0x0000000000428a39 in R_StoreWallRange (start=0, stop=77) at r_segs.c:714
#3 0x0000000000422db0 in R_ClipSolidWallSegment (first=0, last=77) at r_bsp.c:151
#4 0x00000000004231bd in R_AddLine (line=0x7f58fef80c18) at r_bsp.c:355
#5 0x00000000004235f7 in R_Subsector (num=55) at r_bsp.c:539
#6 0x000000000042364b in R_RenderBSPNode (bspnum=32823) at r_bsp.c:563
#7 0x00000000004236b0 in R_RenderBSPNode (bspnum=50) at r_bsp.c:573
...
#15 0x00000000004236b0 in R_RenderBSPNode (bspnum=129) at r_bsp.c:573
#16 0x00000000004236b0 in R_RenderBSPNode (bspnum=382) at r_bsp.c:573
#17 0x0000000000426ae2 in R_RenderPlayerView (player=0x6999c0) at r_main.c:884
#18 0x00000000004044e1 in D_Display () at d_main.c:270
#19 0x0000000000405914 in root () at d_main.c:1203
#20 0x0000000000404e3c in main (argc=2, argv=0x7ffe2d6c72e8) at d_main.c:776
Some readers may recognise the application running here. It is Doom. This stack trace shows part of the 3D engine. At the bottom of the stack, you can see the program's entry point (the "main()" function). At the top, you can see the function that is currently running (R_DrawColumn). In between, you can see the path through function calls that were taken to reach R_DrawColumn: you can see, for instance, that a function called R_RenderPlayerView has been called.
This information can be captured for any process. Here are the steps required:
- attach to the process using gdb. For example:
$ gdb -p 1234
The parameter 1234 is the process ID to attach to. - Enter the command "backtrace" - "bt" for short:
(gdb) bt - Detach from the process.
(gdb) quit
This can be automated. Here is a single shell command that does all of the above in one go:
$ gdb -ex "set pagination 0" -ex "bt" -batch -p 1234
Even a single stack trace is useful. If the program spends most of its time doing X, then logically, at any particular instant, it is very likely to be doing X. However, you may be unlucky. If you misdiagnose a performance problem, you end up wasting a lot of time trying to improve the wrong things. So it's important to get more data.
gdb can be called repeatedly from a bash script, dumping the stack trace into a series of small files:
#!/bin/bash -xe
pid=$1
for x in $(seq 1000 1999)
do
gdb -ex "set pagination 0" -ex "thread apply all bt" \
-batch -p $pid d$x.txt
sleep 0.1
done
This is the poor man's profiler. Yes, it even has a web page. It has the core functionality of a typical profiling tool, because it repeatedly captures the stack of the target process. The sample rate is about 10 captures per second, though this will not be precise, because gdb has to be started each time and there is a significant overhead for that. In a "real" profiler, the time delay would be as precise as possible. But the principle is just the same, and in fact, the poor man's profiler is even more useful than many "real" profilers, because it can be used to profile any program - including ones that are already running!
Scripts like the one above can be used as a quick and dirty way to find out why a program is running slowly without needing to restart it, and that's been useful to me on various occasions, as I try to understand why a test case is taking a long time. I can leave the "profiler" running, have a tea break, and return to hundreds of samples which show what has been happening.
The next question: how best to analyse them? At the moment my favourite method of visualising program performance is a flame graph. The X axis of the flame graph is "samples", the Y axis is "stack depth", and the items on the graph represent functions. For instance, here is a flame graph for Doom:
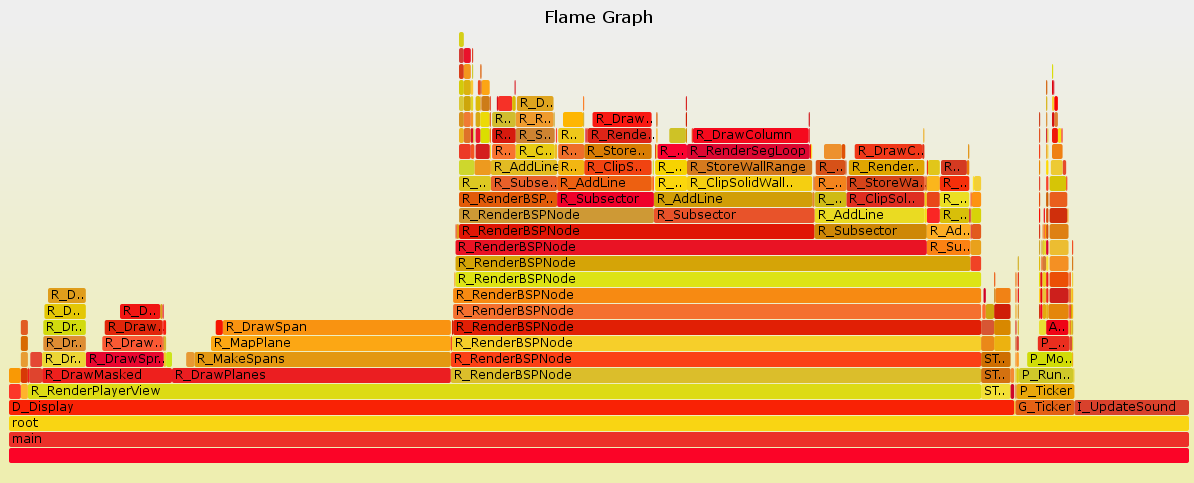
Actually, this is just the top level view of the graph. If you open the SVG file, and Javascript is enabled in your browser, you get to zoom in on one of the functions and explore it. Most of the time is taken up by "R_RenderPlayerView" - perhaps not a surprise, as that is Doom's 3D engine. But you are not forced to look only at the most frequently executed functions. Suppose you are interested in what "G_Ticker" is doing, rather than the 3D engine. You can click on "G_Ticker" and expand it like this:
{kind=link}
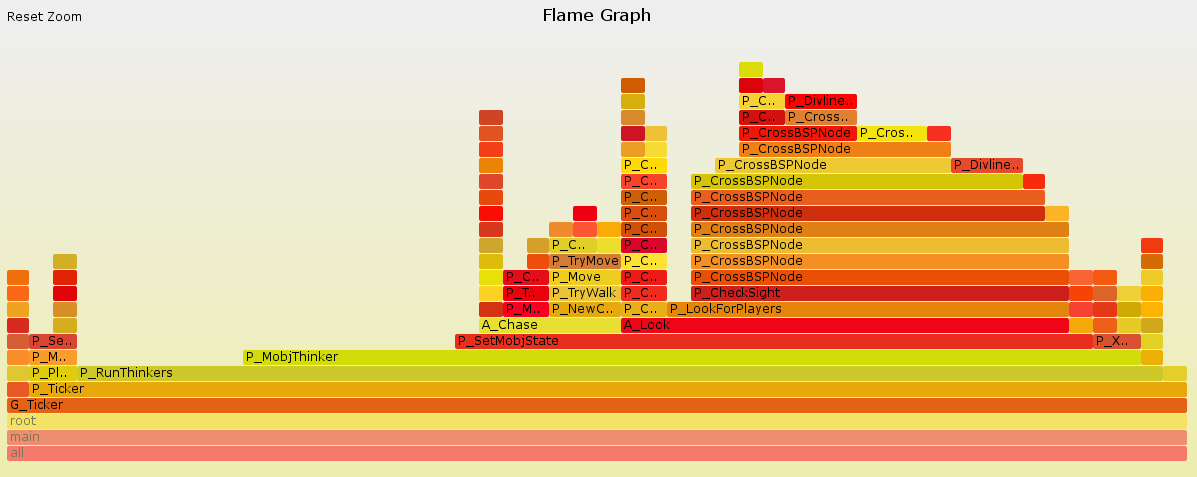
This allows you to see the details. It turns out that G_Ticker spends much of its time running code to control Doom's monsters ("P_MobjThinker"), and much of that time is spent trying to tell if the monster can see the player ("P_LookForPlayers").
Flame graphs are a brilliant way to visualise performance bottlenecks in a program. Problems can be diagnosed effectively. You are unlikely to make a mistake about the cause of a performance problem, because the data is based on many samples, and its presentation does not obfuscate relevant details.
To my pleasant surprise, it turns out that the author of the flame graph software already knows about the "poor man's profiler", and has already implemented support for it. Once you get the flame graph software from Github, only two steps are required to import the gdb output:
$ perl stackcollapse-gdb.pl d*txt tmp.dat
$ perl flamegraph.pl tmp.dat output.svg
This is exactly the process I used to generate the graphs shown above.
Fast problem solving depends on good tools. Credit in this case goes to:
- The "poor man's profiler", which can be used to capture profiling data without restarting or recompiling a program;
- The flame graph software, which can visualise the data captured by the "poor man's profiler", making it easy to diagnose a problem.